
In modern SMP(multicore) systems, any processor can write to a memory location. The other
processors have to update their caches immediately. For that reason, SMP systems implement the concept of "cacheline bouncing" to move "ownership" of cached-data between cores. This is effective but expensive.
Individual cores have private L1 caches which are extremely faster than the L2 and L3 caches which are shared between multiple cores. Typically, when a memory location is going to be ONLY read repeatedly, but never written to (for example a variable tagged with the const modifier), each core on the SMP system can safely store its own copy of that variable in its private(non-shared) cache. As the variable is NEVER written, the cache-entry never gets invalidated or "dirty". Hence the cores never need to get into "cache line bouncing" for that variable.
Take the case of the x86 architecture,
Individual cores have private L1 caches which are extremely faster than the L2 and L3 caches which are shared between multiple cores. Typically, when a memory location is going to be ONLY read repeatedly, but never written to (for example a variable tagged with the const modifier), each core on the SMP system can safely store its own copy of that variable in its private(non-shared) cache. As the variable is NEVER written, the cache-entry never gets invalidated or "dirty". Hence the cores never need to get into "cache line bouncing" for that variable.
Take the case of the x86 architecture,
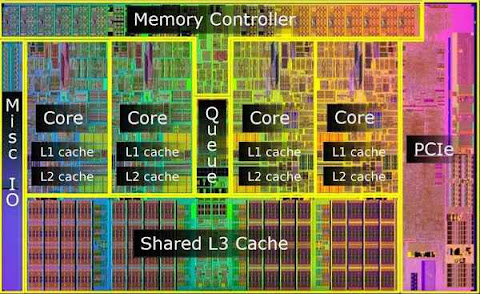 |
| An Intel core i5 die showing the various caches present |
- [NON-SMP] Intel Pentium 4 processor has to communicate between threads over the front-side bus, thus requiring at least a 400-500 cycle delay.
- [SMP] Intel Core processor family allowed for communication over a shared L2 cache with a delay of only 20 cycles between pairs of cores and the front-side bus between multiple pairs on a quad-core design.
- [SMP] The use of a shared L3 cache in the Intel Core i7 processor means that going across a bus to synchronize with another core is NEVER required unless a multiple-socket system is being used.
How __read_mostly is supposed to work:
When a variable is tagged with the __read_mostly annotation, it is a signal to the compiler that accesses to the variable will be mostly reads and rarely(but NOT never) a write.
All variables tagged __read_mostly are grouped together into a single section in the final executable. This is to improve performance by allowing the system to optimise access time to those variables in SMP systems by allowing each core to maintain its own copy of them variable in it local cache. Once in a while when the variable does get written to, "cacheline bouncing" takes place. But this is acceptable as the the time spent by the cores constantly synchronising using locks and using the slower shared-cache would be far more than the time it takes for the multiple cores to operate on own copies in their independent caches.
What actually happens:
This situation is slightly alleviated by the fact that modern cpu caches are mostly 8way or 16way set-associative. In a 16way associative cache, each element has a choice of 16 different cache-slots. This means that two very frequently accessed elements, though closely located in memory, can still end-up in 2 different slots in the cache, thereby preventing cache-thrashing (which would have occurred had both continued competing for the same cache-line slot). In other words a minimum of 17 elements frequently accessed and closely located in memory are required for 2 of them to begin competing for a common cache-line slot.
While this is true in the case of INTEL and its x86 architecture, ARM still sticks to 4way & 2way set-associative caches even in its Cortex A8, which means that just 3 or 5 closely located, frequently accessed elements can result in cache-thrashing on an ARM system. (Update: "Anonymous" rightly points out in the comments that 16-way set associative caches have made their way into modern SoCs, ARM Cortex A9 onwards.)
kernel/arch/x86/include/asm/cache.h contains
kernel/arch/arm/include/asm/cache.h: does NOT, thereby defaulting to the empty definition in
kernel/include/linux/cache.h
UPDATE: The patch daf8741675562197d4fb4c4e9d773f53494203a5 enables support for __read_mostly in the linux kernel for ARM architecture as well.
The reason for this? It turns out that most modern ARM SoCs have started using 8/16-way set associative caches. For example, the ARM PL310 cache controller (as "Anonymous" rightly points out in the comments) available on the ARM Cortex-A9 supports 16-way set associativity. The above patch now makes sense on modern ARM SoCs as the probability of cache-thrashing is reduced by the larger "N" in the N-way associative caches.
With the number of cores increasing rapidly and the on-die cache size growing slowly, one must always aim to:
All variables tagged __read_mostly are grouped together into a single section in the final executable. This is to improve performance by allowing the system to optimise access time to those variables in SMP systems by allowing each core to maintain its own copy of them variable in it local cache. Once in a while when the variable does get written to, "cacheline bouncing" takes place. But this is acceptable as the the time spent by the cores constantly synchronising using locks and using the slower shared-cache would be far more than the time it takes for the multiple cores to operate on own copies in their independent caches.
What actually happens:
(NOTE: In the following section, "elements" refers to memory blocks which are are smaller than a single cache-line and are so sparse in main-memory that a single cache-line cannot contain them both simultaneously.)
The problem with the above approach is that once all the __read_mostly variables are grouped into one section, the remaining "non-read-mostly" variables end-up together too. This increases the chances that two frequently used elements (in the "non-read-mostly" region) will end-up competing for the same position (or cache-line, the basic fixed-sized block for memory<-->cache transfers) in the cache. Thus frequent accesses will cause excessive cache thrashing on that particular cache-line thereby degrading the overall system performance.This situation is slightly alleviated by the fact that modern cpu caches are mostly 8way or 16way set-associative. In a 16way associative cache, each element has a choice of 16 different cache-slots. This means that two very frequently accessed elements, though closely located in memory, can still end-up in 2 different slots in the cache, thereby preventing cache-thrashing (which would have occurred had both continued competing for the same cache-line slot). In other words a minimum of 17 elements frequently accessed and closely located in memory are required for 2 of them to begin competing for a common cache-line slot.
While this is true in the case of INTEL and its x86 architecture, ARM still sticks to 4way & 2way set-associative caches even in its Cortex A8, which means that just 3 or 5 closely located, frequently accessed elements can result in cache-thrashing on an ARM system. (Update: "Anonymous" rightly points out in the comments that 16-way set associative caches have made their way into modern SoCs, ARM Cortex A9 onwards.)
kernel/arch/x86/include/asm/cache.h contains
#define __read_mostly __attribute__((__section__(".data..read_mostly")))
kernel/arch/arm/include/asm/cache.h: does NOT, thereby defaulting to the empty definition in
kernel/include/linux/cache.h
#ifndef __read_mostly
#define __read_mostly
#endif
UPDATE: The patch daf8741675562197d4fb4c4e9d773f53494203a5 enables support for __read_mostly in the linux kernel for ARM architecture as well.
The reason for this? It turns out that most modern ARM SoCs have started using 8/16-way set associative caches. For example, the ARM PL310 cache controller (as "Anonymous" rightly points out in the comments) available on the ARM Cortex-A9 supports 16-way set associativity. The above patch now makes sense on modern ARM SoCs as the probability of cache-thrashing is reduced by the larger "N" in the N-way associative caches.
With the number of cores increasing rapidly and the on-die cache size growing slowly, one must always aim to:
- Minimise access to the last level of shared cache to improve performance on multicore systems.
- Increase associativity of private caches (of individual cores) to eliminate cache-slot contention and reduce cache-thrashing.
The ARM PL310 cache controller, used in a number of SoCs with Cortex A9 MPcore CPU's is 8- or 16-way set associative (depending on how the RTL was configured).
ReplyDeleteI'm not sure why you think "ARM still sticks to 4way & 2way".
Ahh! ...and THATS why the above patch was added to the Linux Kernel for ARM. Thank for pointing this out. It would be interesting if we could profile a recent kernel on... say the OMAP3 which has 16KB 4way I and D caches on its CortexA8 and observe if common workloads produce any significant difference with and without the above patch applied...
DeleteBut yes, Cortex A9 and above, we no longer need to worry about this being a problem indeed. :-)
But then again going back to the docs i had originally referred, the 2,4-WAY associativity of ARM caches seems to still continue in the CortexA9/A15 families.
DeleteDetails of the CPU caches on:
ARM Cortex A9
Samsung Exynos 5250 (Dual Cortex A15)
How to understand "This increases the chances that two frequently used elements will end-up competing for the same position."? For example, two variables in adjacent cachelines are in different cache-line set, so one will not competing cache slots of another.
ReplyDeleteConsider the situation without "__read_mostly". There is a certain distribution of element in memory spread over multiple cachelines. By picking a bunch of these elements tagged with "__read_mostly" and placing them elsewhere, now the remaining elements are packed together closer - i.e. some of the elements that were previously on separate cachelines are now mapped into a single cacheline.
Delete